Hi Patrick,
On Sat, Oct 2, 2021 at 11:48 AM Patrick L. Francis <wxprofessor@xxxxxxxxx>
wrote:
> So if you run 180GB queues at ucar, you clearly have a reason for doing
> so.. could you expand on that logic please? :)
>
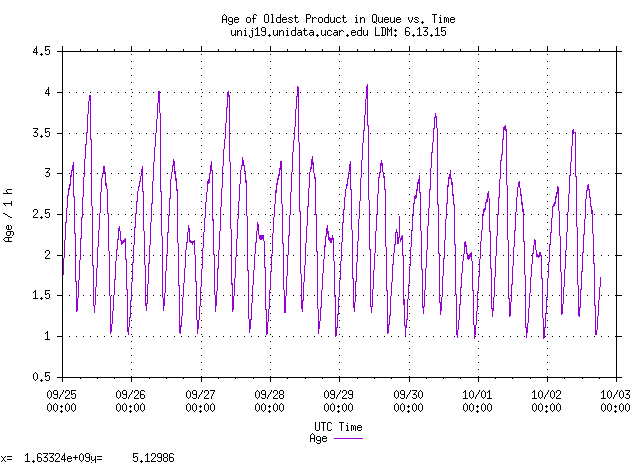
That size is what's necessary in order to hold at least the last hour's
worth of data. Here's a time-series plot of the age of the oldest product
in one of our queues from "ldmadmin plotmetrics -b 20210925":
[image: image.png]
> Surely supporting duplicate product detection would be one reason, and
> perhaps the ability to support downstream feeds if they need to rebuild
> their own queues during periods of unforseen downtime?
>
You've got it.
--Steve